

I recently concluded my internship with the Data Science team at Traindex. One of the tasks assigned to me was replicating the ML-based semantic search technique. The Data Science team had implemented this on their Traindex search API.
Traindex uses document similarity techniques like LSI and Doc2Vec to train a model that can identify the best matching documents with a given document or paragraphs or phrases.
One of the most challenging tasks is the benchmarking of language models. The process sometimes requires using a series of techniques for proper evaluation and testing. One of the benchmarks used for Traindex is Jaccard Similarity. It provides a baseline and is not enough for a complete evaluation of any model.
This article intends to give some background on the where and how of the Jaccard Similarity score. It is useful for creating benchmarks to measure the performance of their language models.
Text Similarity
Text similarity can help us determine the similarity between pairs of documents, or a specific document and a set of other documents. The score calculated by performing the similarity check decides model acceptance, improvement, or rejection. The categorization of string-based text similarity shows various approaches that fit according to the scenario.

There are two main alternatives for finding the similarity metric.
-
The Character-based approach deals with the individual characters present in the document with the proper sequence.
-
The Term-based deals with the whole word. The words are often simplified or lemmatized before performing the test as per the initial data cleaning process used for the training purpose.
Introduction - Jaccard Index
For the comparison of a finite number of elements between two observations, it is common practice to count items that are common to both sets. It is a natural fit for comparing posts in case of the representative tags to measure how similar two articles are in terms of tags.
The Jaccard similarity index, also the Jaccard similarity coefficient, compares members of two sets to see shared and distinct members. It is a measure of similarity for the two sets of data, with a range from 0% to 100%. The higher the percentage, the more similar the two populations. The Jaccard Index is a statistic to compare and measure how similar two different sets are to each other. Although it is easy to interpret, it is susceptible to small sample sizes. It may give erroneous results, especially with smaller samples or data sets with missing observations.
Let's have a look on this example.
from gensim.matutils import jaccard
print(jaccard(bow_water, bow_bank))
Out: 0.8571428571428572
print(jaccard(doc_water, doc_bank))
Out: 0.8333333333333334
print(jaccard(['word'], ['word']))
Out: 0.0
The three code examples above feature two different input methods.
In the first case, we present to Jaccard document vectors already in the bag of words format. The distance's definition is one minus the size of the intersection upon the size of the union of the vectors. We can see that the distance is likely to be high - and it is.
The last two examples illustrate the ability for Jaccard to accept even lists (i.e. documents) as inputs. In the previous case, because they are the same vectors, the value returned is 0 - this means the distance is 0 and the two documents are identical.
Mathematical Representation
Mathematically, it is a ratio of intersection of two sets over the union of them. In the case of textual documents or phrases, it compares the words and counts the common words. Then divides it with the total number of words present in both of the documents. The same method applies to more than two documents with the same technique.
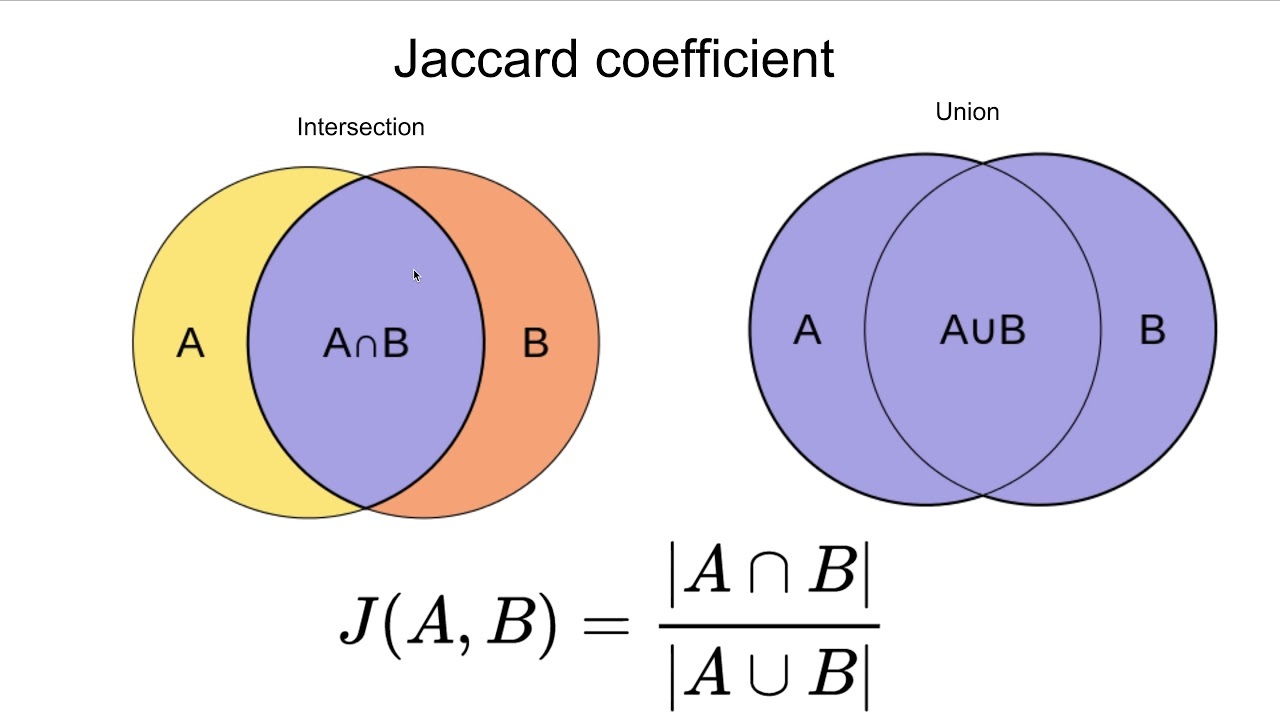
From the venn diagram above, it can be concluded that:
Jaccard Index = (number in both sets) / (number in either set) * 100
Benchmarking is an essential process of Data Science that indicates the confidence level and effectiveness of a model. Traindex performs multiple benchmarking techniques from which Jaccard means similarity testing is an important one.
A test data set finds the mean similarity score for the trained model. Sampling the main dataset where the validation fraction provides the parameter in the config file. Leaving every feature aside, UCID i.e., the unique document ID and the whole text, are the two crucial columns that are necessary to perform the testing.
The following steps test the LSI model performance on the basis of term-based similarity:
- The test data is made containing the UCIDs with their respective text where the sampling is done according to the size mentioned in the configuration file.
- Cleaning of the text column of the test data as per the requirements, while the removal of duplicate terms is compulsory. For each document, the query is made by using the text corresponding to its UCID.
- The document and index are sent to a function that returns the no of common words present in the query and document with the help of indices.
- Meanwhile, the calculations for common words and the total observations are done, followed by the calculation for Jaccard similarity by taking the ratio of the lengths saved earlier.
- Following the above steps can produce the adequate results required for the evaluation, but the results are scaled by dividing the score with respective query size. The extra step eradicates the behavioral bent of results because of different query size.
At last, the mean similarity score for all the combined results is calculated by averaging.
A data frame is optional but populated with the similarity score for each result. The values are mapped on the bar chart, which clearly shows the percentage similarity with particular UCID, as shown in the sample figure.

Impact of Jaccard Similarity as an Evaluation Metric
The Jaccard similarity score may not be the best solution for benchmarking, but it may be considered for the following advantages:
- Jaccard similarity takes a unique set of words for each sentence. This means that if you repeat any word in the sentence several times, Jaccard's similarity remains unchanged. Consider these two sentences:
Sentence 1: AI is our friend, and it has been friendly.
Sentence 2: AI and humans have always been friendly.
It is robust enough to cater repetitions of a word like the word "friend" in sentence 1. No matter how much frequent any word is, Jaccard's similarity will be the same - here it is 0.5.
-
Instead of rejecting or accepting the document for a given set of queries, It provides a numerical score ranges from 0 to 1, which provides a clear view and can be used as a lookup for further iterations. Figure 3 explains the closeness of random search queries with the same document where the height of the bars represents the Jaccard similarity scores between queries and the document.
-
Jaccard similarity is useful for cases where duplication does not matter. For example, it will be better to use Jaccard similarity for two product descriptions as the repetition of a word does not reduce their similarity.
In a nutshell, benchmarking for evaluating a set of models is a necessary step in the data science process. The development of various tools and approaches for the calculation of a metric that can differentiate between products is important. In comparison with other domains, evaluation of Machine Learning, the language and contextual models are difficult. When there is less number of benchmarking techniques for textual models, the Jaccard similarity score is an important performance evaluation metric that can help in providing a partial summary of the model. It can be concluded that the effectiveness of any benchmarking technique depends on how good they fit the problem. Also, to understand that a mismatch between the metric and the case can misguide the results.



